Relational Database Management System (RDBMS) Scaling - II
Service Oriented Architecture (SOA) and Microservices
Service Oriented Architecture
Partitioning splits data of the same type into separate, unrelated groups.
Service Oriented Architectures (SOA) do something different. They partition
both the data and the codebased on type and function. Like with partitioning, no joins can automatically be performed across these partitions.
Stack
The primary concept behind SOA is having many focused mini-applications (microservices). Each of these focused mini-applications is called a service. When a front-end application server needs data to satisfy a request, instead of speaking to a database, it will request data from the appropriate service.
Functions
Each service is broken out by logical function. E.g.:
- Users service that handles
authenticationandauthorization - Billing service that handles
credit cardsandsubscriptions - Account subsystem that tracks
invoices
Communications
With partitioning the application server often only talks to a single partition per request. With SOA the front-end application server may communicate with many distinct services, and some of those services may talk to a handful of other services.
Benefits
With SOA the deployment of services is decoupled. That means that each can be updated and scaled independently of the remainder of the system. This decoupling can provide isolated outages (billing is down for 5 minutes).
Services lend themselves well to maintenance by a single development team thus minimizing conflicts between teams that would otherwise collectively work on a single monolithic application.
SOA the Demo App
Designs
- Comments service can track comments and replies for each submission.
- Submissions service can be responsible for all the links that are submitted.
- Communities service can store the list of communities along with their creator.
- Users service can manage the users in the system.
Code
Before
1 | class CommunitiesController < ApplicationController |
After
1 | class CommunitiesController < ApplicationController |
SOA Implementation
SOA is often implemented by JSON over HTTP. RESTful APIs are common.
Why JSON/REST/HTTP?
It’s very easy to do. In fact, rails makes you do work in order to not have a JSON API (assuming you are using rails generate). JSON APIs over HTTP are easily discovered. This permits (but doesn’t necessitate) less documentation as the API may be intuitive enough to use without knowing much more than the endpoints and their input. Using JSON/HTTP permits a shared technology stack. Rails on the front-end application servers, and Rails on the servers hosting the services.
Alternatives to JSON/HTTP/Rest
The primary issue with JSON/HTTP/REST is performance. For high-performance internal APIs there are a few excellent options:
- Protocol Buffers (developed by Google)
- Apache Thrift (developed by Facebook)
High performance APIs often trade flexibility for performance. For instance they may require strongly typed data and as a result require more documentation.
Encoding Data
- Language specific:
- JAVA - java.io.Serializable
- Ruby - Marshal
- Python - pickle
- JSON, Apache Avro, XML, CSV, Binary
- Apache Thrift and Protocol Buffers
Modes of Dataflow
- Via Databases
- Via Service Calls (RPC, REST, GraphQL)
- Via Async message passing (message brokers: IBM WebSphere, RabbitMQ, ActiveMQ, Apache Kafka, NATS, TIBCO)
SOA Trade-offs
Strengths
- Small encapsulated code-bases
- Scales well as application size scales
- Scales well as the number of teams scale
Weaknesses
- May not scale with the number of users (e.g., increased load to authentication service)
- Transactions across services do not exist
- Consistent DB snapshots across services do not exist
- Application logic required to join data
Separating Reads from Writes
Database Operations
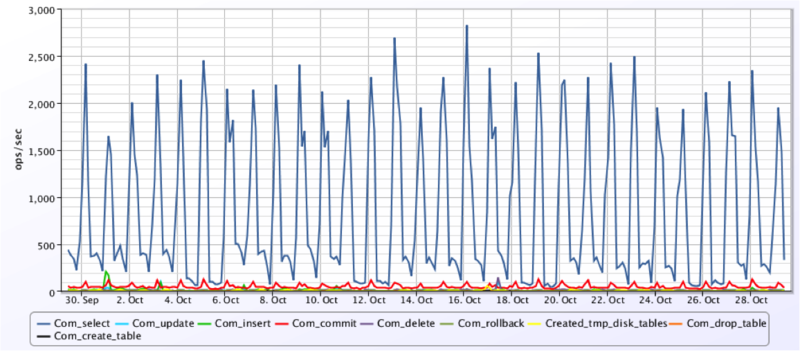
This graph shows significantly more reads than writes. This may be the case for your application.
Database Horizontal Scaling
Methdology
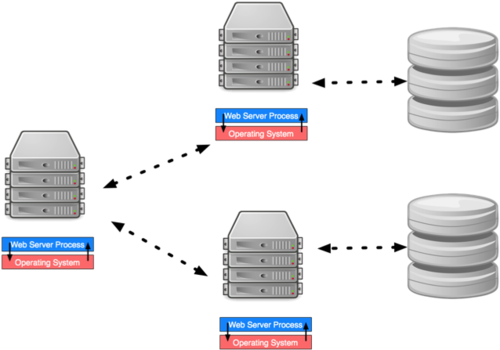
In general, a relational database is hard to horizontally scale. However, when limited to a read-only copies, databases are very easy to horizontally scale.
- Set up separate machines to act as read replicas
- Whenever any transaction commits to the primary database, send a copy to each replica and apply it
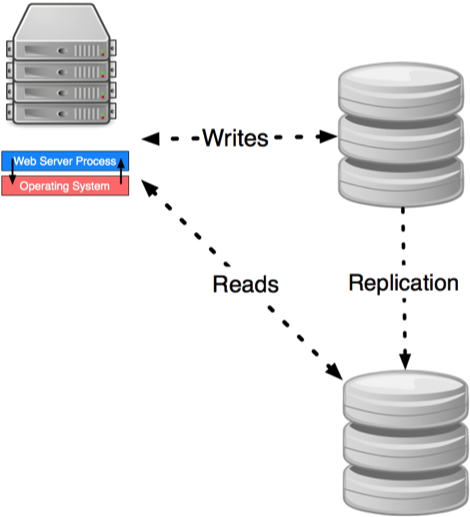
Replication
Occurring Time
The sending of data from the primary to its replicas (replication) can happen either synchronouslyor asynchronously.
Synchronous
When a transaction is committed to mater, the primary sends the transaction to its replicas and waits until applied by all before completing.
Pro: Consistency. Subsequent read requests will see changes.
Con: Performance. There may be many read replicas to apply changes to.
Asynchronous
When a transaction is committed to the primary, the primary sends the transaction to its replicas but does not wait to see if the transaction is applied.
Replication Levels
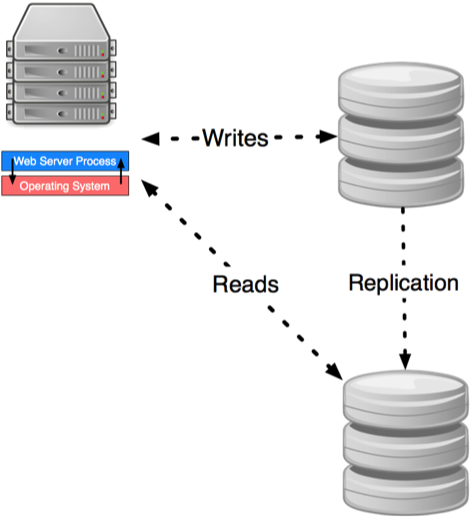
Statement-level
Similar to streaming the journal from the primary to its replicas.
Block-level
Instead of sending the SQL statements to the replicas, send the consequences of those statements. (The replicas only store the value of records)
Trade-offs
Statement-level is faster than block-level, with a catch.
An SQL statement is generally more compact than its consequences.
1 | UPDATE txns SET amount=5; |
The above query acts on all rows which may require a lot of data to transmit the consequences.
However, SQL statements must now be deterministic:
1 | UPDATE txns SET amount=5, updated_at=NOW(); # What is the value of NOW()? |
Such values must be communicated from the primary to its replicas.
PostgreSQL Replication
PostgreSQL streaming replication is
asynchronousby default. If the primary server crashes then some transactions that were committed may not have been replicated to the standby server, causing data loss. The amount of data loss is proportional to the replication delay at the time of failover.When requesting synchronous replication, each commit of a write transaction will wait until confirmation is received that the commit has been written to the transaction log on disk of both the primary and standby server. The only possibility that data can be lost is if both the primary and the standby suffer crashes at the same time. This can provide a much higher level of durability, though only if the sysadmin is cautious about the placement and management of the two servers. Waiting for confirmation increases the user’s confidence that the changes will not be lost in the event of server crashes but it also necessarily increases the response time for the requesting transaction. The minimum wait time is the roundtrip time between primary to standby.
https://www.postgresql.org/docs/9.1/warm-standby.html#SYNCHRONOUS-REPLICATION
Demo App and Read Replicas
read replicas
The following pages would be served from read replicas:
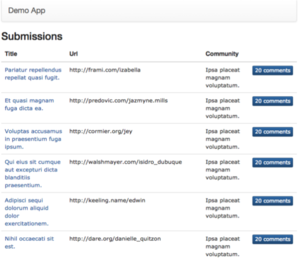
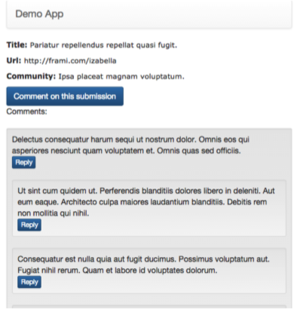
primary database
The controllers associated with the actions from following pages (create) would need to talk to the primary database.
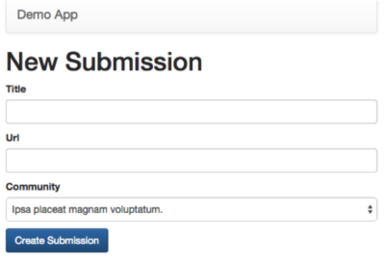
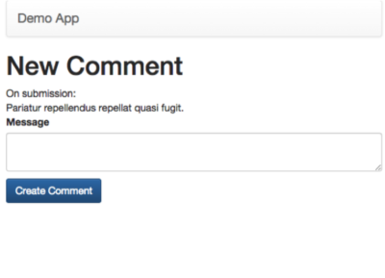
Rails Read Replica Support
Rails 6 has first-class support for read replicas now. “Automatic switching” must be explictly configured and enabled:
Automatic switching allows the application to switch from the primary to replica or replica to primary based on the HTTP verb and whether there was a recent write.
If the application is receiving a POST, PUT, DELETE, or PATCH request the application will automatically write to the primary. For the specified time after the write the application will read from the primary. For a GET or HEAD request the application will read from the replica unless there was a recent write.
Rails guarantees “read your own write” and will send your GET or HEAD request to the primary if it’s within the delay window. By default the delay is set to 2 seconds. You should change this based on your database infrastructure. Rails doesn’t guarantee “read a recent write” for other users within the delay window and will send GET and HEAD requests to the replicas unless they wrote recently.
Trade-offs of Read Replicas
Strengths
For applications with a high read-to-write ratio:
- the load on the primary database can be dramatically reduced.
- read replicas can be horizontally scaled (even with a load balancer)
Weaknesses
Application developer needs to think about reads that affect writes vs. reads that do not affect writes as such dependent reads should occur in the same transaction as the write.